Dlaczego takie wysokie obciążenie VPS?
Lempik | 2021-01-01 15:15:44 UTC | #1
Ślędzę od 2 minut program htop i ciągle rośnie load average. Włączyłem też top, czy przypadkiem steal nie jest wysoki, ale nie - waha się w okolicach 0,3 - 0,9 st.
Dlaczego mam takie wysokie load average i podczas mojej obserwacji wzrosło z ok. 1,8 do 3,18, choć oba rdzenie CPU były do 10%?
Zanim napisałem to pytanie, to load average spadło do 0,11. Myślałbym, że coś pięć minut temu VPS robił, ale martwi mnie właśnie to, że ta wartość ciągle rosła, chociaż CPU 1 i 2 leniuchowały.

Axerr | 2021-01-01 12:17:16 UTC | #2
Użycie CPU a load to dwie zupełnie inne rzeczy.
Użycie CPU to aktualnie używane zasoby procesora, w tej chwili.
Load to wykazana w liczbie “praca”, którą komputer musi właśnie wykonuje, load pokazuje obciążenie CPU w danym okresie czasu.
Pierwsza wartość pokazuję średnią pracę z 1 monuty, druga z 5 minut, natomiast trzecia z 15 minut.
Lempik | 2021-01-01 12:21:55 UTC | #3
No i co jest przyczyną tego wysokiego load average? Jaką pracę mógł serwer robić i kto ją robił, skoro oba rdzenie były poniżej 10%?
Axerr | 2021-01-01 12:57:53 UTC | #4
https://serverfault.com/questions/365061/high-load-average-low-cpu-usage-why/524818
https://askubuntu.com/questions/1238395/high-load-average-but-low-cpu-from-top
https://unix.stackexchange.com/questions/405636/high-load-but-low-cpu-usage/468512
SystemZ | 2021-01-01 13:11:13 UTC | #5
Warto zauważyć, że loadavg to nie tylko średnie zużycie CPU:
https://en.m.wikipedia.org/wiki/Load_(computing)
Na load wpływa również ilość zadań w kolejce czy też I/O czyli ogólnie przepływ danych więc zazwyczaj będzie trzeba też zerknąć na to co dzieje się z dyskiem, czy nie jest nadużywany np. przy użyciu iotop, najlepiej z flagą która pokazuje tylko aktywne obecnie aplikacje czyli iotop -o.
W przypadku serwerów gier, w ticketach widzieliśmy kilka przypadków gdzie serwery MC dostawały czkawki, np. na 2-3 sek gdzie zużywały 100% CPU, właściciel pomijał obserwację CPU przez kilka minut a wykresy Proxmox pokazują tylko średnią więc nie było widać tych “peaków”, wynikiem był niski TPS.
Lempik | 2021-01-01 15:06:42 UTC | #6
Teraz już innych pomiarów nie zrobię, ale w tym momencie na serwerze nic sie nie działo. Swój wpis wysłałem o 7:39, MC był uruchomiony od 7:14, zero graczy na serwerze MC. Kopię zapasową zrobiłem o 6:33-6:38, za pomocą ftp pobierałem dwa pliki .tgz na swój komputer od 6:38 do 7:01 (bo takie są timestampy tych 2 plików na moim komputerze). Czyli co najmniej od 10 minut nic na serwerze nie powinno się dziać (od restartu serwera MC minęło co najmniej 10 minut).
Oprócz MC mam na serwerze nginx z bardzo prostą, wręcz statyczną stroną www oraz PufferPanel, tylko że nic nie robiłem (nie odnawiałem strony www z PufferPanelem, może raz - żeby się przekonać, że naprawdę nikt nie jest zalogowany na serwerze MC). Na dysku mam 3,7 GB wolnego miejsca z 25 G.
Załączam resztę zrzutu htop z rana.
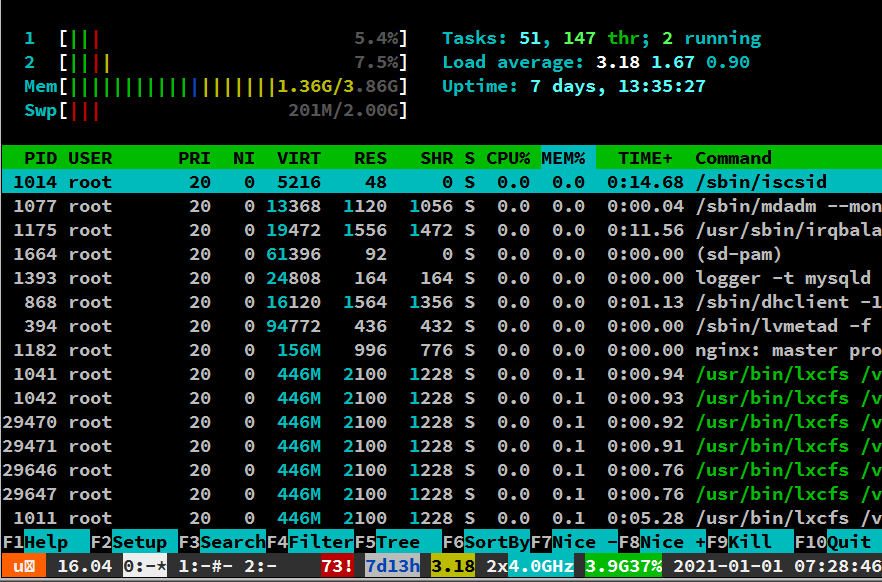
Czyli co mam sprawdzać następnym razem, jeżeli taka sytuacja nastąpi? Jak mogę ustalić, co jest przyczyną?
SystemZ | 2021-01-04 17:48:18 UTC | #7
Generalnie najpierw ustaliłbym to czy realnie ten duży load Ci przeszkadza.
Przykładowo w przypadku typowego serwera WWW trochę większy load po prostu odrobinę opóźni ładowanie strony co specjalnie nie przełoży się jakoś negatywnie na odczucia użytkowników.
Loadavg nie jest idealnym licznikiem, miałem sytuacje gdzie load na 8 wątkowym serwerze wynosił 500 ale nadal działał sprawnie, choć przyznam że są to dość rzadkie i dość niestandardowe sytuacje.
Jeśli zauważysz, że duży load Ci przeszkadza np. niższy TPS w MC to będziesz potrzebować więcej danych o wydajności w czasie więc ogólnie zaczyna się temat monitoringu.
Na początek dość łatwym (i darmowym) rozwiązaniem będzie Netdata
https://www.netdata.cloud/
Istnieją też “prostsze” narzędzia które nie robią bałaganu w systemie (wedle mojej skali) ale to wymaga trochę więcej konfigurowania, np. Prometheus jest darmowy, wolny i szeroko wspierany:
https://prometheus.io/docs/introduction/overview/
i ma sporo integracji - “exportery”
https://github.com/sladkoff/minecraft-prometheus-exporter
Można sobie dodać np. TPSy do monitorowania i jeśli spadną to otrzymać powiadomienie na telefonie.
Taki setup to jeszcze kwestia kilku elementów: alertmanager (alarmy dla prometheusa) i usługi na telefon typu Pushover czy Pushbullet
https://pushover.net/
https://www.pushbullet.com/
Lempik | 2021-01-04 18:44:03 UTC | #8
[quote=”SystemZ, post:7, topic:17296”]
Generalnie najpierw ustaliłbym to czy realnie ten duży load Ci przeszkadza.
[/quote]
W tej chwili nikogo na serwerze nie było, czyli nikomu nic nie zaszkodziło. Przeszkadza mi to w tym sensie, że to była jakaś nadzwyczajna sytuacja, nie wiedziałem, czy tam się nie dzieje bez mojej wiedzy coś nielegalnego, za co mógłby mój VPS zostać zablokowany (np. jakieś oprogramowanie wysyłające spamy).
SystemZ | 2021-01-04 23:14:06 UTC | #9
Tu trudno doradzić kompleksowo w kilku zdaniach.
Generalnie warto sprawdzać co jakiś czas logi systemowe journalctl -f, chociażby zerknąć w poszukiwaniu słowa “error” czy “warning” i wpisywać je w wyszukiwarkę gdy wystąpią, uprzednio usuwając poufne dane.
Jeśli chodzi o malware to z pewnością zerknąłbym czy zużycie CPU w htop i Proxmox się pokrywa.
Zużycia CPU pokazanego w Proxmox malware nie da rady oszukać, co do aplikacji w systemie, różnie bywa, jedna z zalet posiadania VPS zamiast dedyka :slight_smile:
Czytałem o przypadkach podmiany systemowych binarek na “lewe” z fałszywymi wynikami oraz trefne jądro które maskowało co chciało. Zazwyczaj jednak po prostu przybierają nazwę zaufanej aplikacji (np. w htop wygladają jak apache) i zużywają sporo CPU (te bardziej przebiegłe nie zawsze stałe 100%) to temat na długie godziny czytania i raczej osobny wątek jak inni sobie radzą z malware 
Lempik | 2021-01-05 07:06:32 UTC | #10
[quote=”SystemZ, post:9, topic:17296”]
Generalnie warto sprawdzać co jakiś czas logi systemowe journalctl -f
[/quote]
Oczywiście tego polecenia nie znałem. Teraz spróbowałem i widzę:
Jan 05 07:58:48 Received disconnect from 218.29.54.87 port 56045:11: Bye Bye [preauth]
Jan 05 07:58:48 Disconnected from 218.29.54.87 port 56045 [preauth]
Jan 05 07:58:49 Failed password for root from 112.85.42.188 port 58331 ssh2
Jan 05 07:58:51 Failed password for root from 112.85.42.188 port 58331 ssh2
Jan 05 07:58:51 Received disconnect from 112.85.42.188 port 58331:11: [preauth]
Jan 05 07:58:51 Disconnected from 112.85.42.188 port 58331 [preauth]
Jan 05 07:58:51 PAM 2 more authentication failures; logname= uid=0 euid=0 tty=ssh ruser= rhost =112.85.42.188 user=root
Jan 05 07:58:57 Invalid user user from 119.147.42.82
Chyba same chińskie adresy.
Timo | 2021-01-05 18:21:54 UTC | #11
To akurat normalne. Codziennie setki jak nie tysiące botów próbują dostać się do SSH.
Dlatego ważne jest bezpieczne hasło, a najlepiej klucz SSH. Dodatkowo polecam zainstalować fail2ban, który po kilku nieudanych logowaniach z jednego adresu zablokuje go.
Lempik | 2021-01-05 18:24:15 UTC | #12
[quote=”Timo, post:11, topic:17296”]
polecam zainstalować fail2ban, który po kilku nieudanych logowaniach z jednego adresu zablokuje go.
[/quote]
Dzięki. To już zainstalowałem ponad 2 lata temu, kiedy mi na forum pomagaliście z instalacją mojego pierwszego VPS.
system | 2021-02-06 18:24:21 UTC | #13
Ten temat został automatycznie zamknięty 32 dni po ostatnim wpisie. Tworzenie nowych odpowiedzi nie jest już możliwe.